
Introduction
The policy update procedure in the masterfiles policy framework is fairly straightforward - copy all files matching $(update_def.input_name_patterns) from hub’s $(sys.masterdir) directory to clients $(sys.inputdir) directory. Copying everything everywhere and then use some selection (or “classes”) to determine what to do is fine at beginning. My first solution to manage computers in some computer system or landscape was to use “IPv4_*” (or hostname) classes, that pretty soon became hard to maintain and very hard to change. So, I needed a new model that improves maintainability and deployment flexibility of policy. This extension of update procedure enables each computer in some landscape or system to receive and execute only those policies that are specific to it. This improves maintainability and makes systems less cluttered with unneeded information/files. This model extends the existing update procedure to fetch client specific policy files from a separate repository directory on hub (outside $(sys.masterdir)). It copies policies to “$(sys.inputdir)/services/autorun” directory on client. Thanks the “autorun” and “augments” features this approach is easy to implement.
Tags
The first thing to consider is tagging the CFEngine clients. Tags are very practical and flexible way to uniquely identify (i.e. server1, server2, etc.) and/or group (i.e. redhat, database, etc.) computing resources. In order to assign unique set of tags to each CFEngine client, I recommend putting them into a file outside $(sys.masterdir) and $(sys.inputdir) directories or when inside to use file with extension not matching $(update_def.input name patterns). I.e. my implementation uses “$(sys.workdir)/node.tags” file and I do not use masterfile policy update procedure to manage it - more on implementations of tags file is explained in “how to tag” topic. Beside those from the tags file, my implementation uses IP address and hostname as tags too.
How it works
To implement this concept I wrote jb_update_policy3.cf (it is my 3rd version). It uses CFEngine idea of validation timestamp (cf_promises_validated) to determine if files are to be copied from hub and thus avoid heavy traffic on server and in network. On client side, this policy copies files from multiple source subdirectories and it has to take care of multiple timestamp validation files. On the hub, it has to check for changes on the policies inside repository subdirectories (which are named after tags, IPs and/or hostnames) and update validation timestamps in them. There is also a requirement to build a directory structure (named after tags, IPs and/or hostnames) in the other repository on the hub containing policy files to be distributed to remote agents. When, for example, required tag named subdirectory in that repository is not available on the hub, nothing gets copied (and promise not kept is indicated in agent verbose output). Some meaningful naming convention for policy files is required in order to avoid overwriting because they all get copied to same “service/autorun” subdirectory. NOTE “Autorun” policies are not required to be in the “service/autorun” subdirectory. Any bundle found in inputs with the autorun tag will be run automatically.
Schema
This diagram shows where a client copies files from the secondary
policy repository based on its tags.
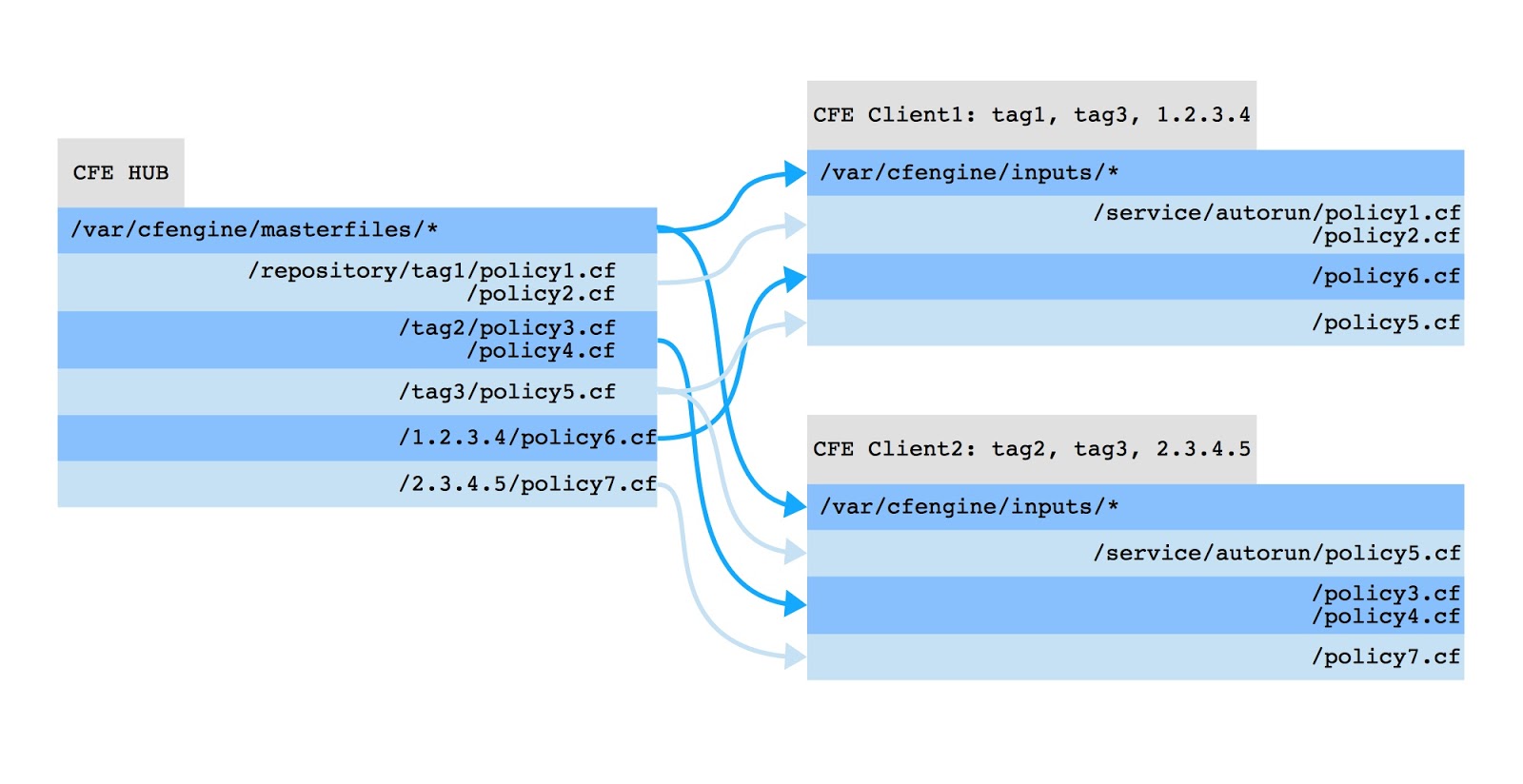 In
this schema, each of the two CFEngine clients has two tags and uses IP
address to fetch policy files from correspondingly named subdirectories
in repository directory. Note that “tag3” is common to both clients.
In
this schema, each of the two CFEngine clients has two tags and uses IP
address to fetch policy files from correspondingly named subdirectories
in repository directory. Note that “tag3” is common to both clients.
Implementation
The implementation uses the augments file (aka def.json) to define needed variables.
{
"classes" : {
"services_autorun" : [ "any" ]
},
"vars" : {
"jb_repository_dir" : "$(sys.workdir)/repository",
"jb_repository_perms" : "0600",
"node_tags_file" : "$(sys.workdir)/node.tags"
}
}ACLs for serving files from the secondary repository are defined in “jb_repository_acl_rules.cf” which is included via “promises.cf”.
bundle server jb_repository_acl_rules
{
access:
any::
"$(def.jb_repository_dir)"
handle => "server_access_grant_access_jb_repository_dir",
comment => "Grant access to the JB repository",
admit => { @(def.acl) };
}The update.cf policy that ships in the stock Masterfiles Policy Framework must be extended to include “jb_update_policy3” in the bundlesequence.
body common control
{
bundlesequence => {
"update_def",
"u_cfengine_enterprise",
@(u_cfengine_enterprise.def),
"cfe_internal_dc_workflow",
"cfe_internal_bins",
"cfe_internal_update_policy",
"cfe_internal_update_bins",
"cfe_internal_update_processes",
"jb_update_policy3"
};
version => "update.cf $(update_def.current_version)";
inputs => {
@(cfengine_update_controls.update_def_inputs),
"cfe_internal/update/update_bins.cf",
"cfe_internal/update/cfe_internal_dc_workflow.cf",
"cfe_internal/update/cfe_internal_local_git_remote.cf",
"cfe_internal/update/cfe_internal_update_from_repository.cf",
"cfe_internal/update/update_policy.cf",
"cfe_internal/update/update_processes.cf",
"jb_update_policy3.cf"
};
# Uncomment to connect to the hub using latest protocol.
#protocol_version => "latest";
}Since I am using the “autorun” feature of the Masterfiles Policy Framework each of the agent bundles in my secondary repository is tagged.
meta:
"tags" slist => { "autorun" };How to classify hosts (“tagging”)?
There are multiple ways to set up or prepare the tags file content depending on the specific infrastructure (physical computer, VM, container or cloud). Here are some of my ideas on this. In my opinion, manually adding or managing content of the tags file is an option only for testing or lab environment but not for production (or even some relatively small number of CFEngine clients). A better way would be to let CFEngine to manage tags somehow. I.e. IP, hostname or MAC could be considered as tags and used directly. Another idea on managing tags is to make it 2-phased job. First phase would be to (re)distribute tags to the CFEngine clients using certain criteria and let some policy (re)write content of tags file which will be followed by second phase - fetch and run “autorun” policies according to tags. Cloud appliances, like AWS, could use user data file. Since content of this file could be a shell or “cloudinit” script, it is possible to use it to populate content of tags file once instance is started. Consider following simple AWS example:
#!/bin/sh
<eventually install CFE and bootstrap it, if image not already prepared>
echo "tag1;tag2" > /var/cfengine/node.tagsIn AWS, it is possible to set tag values as user data, fetch them at boot time (i.e. curl http://169.254.169.254/latest/user-data/) and write down to the tags file or it to use them directly in some update policy script - BTW from version 3.8.0 there is url_get() function in CFEngine. A container appliance like Docker has a feature for mounting single files, meaning a tag file could be prepared outside the container and then mounted and used by CFEngine client running inside container. Something like this:
files:
"$(tags_file_dir)/container1.tags"
comment => "Creates tags file for container1",
create => "true",
edit_defaults => empty,
edit_line => insert_lines("tag1;tag2");
commands:
"/usr/bin/docker run --volume $(tags_file_dir)/container1.tags:/var/cfengine/node.tags ..."
comment => "Running container container1";Hub side of the story
This policy update procedure needs prepared and maintained directory structures and policies in repository on the CFEngine hub where clients can look for and copy those policy files. Manual maintenance is of course out of question except for maybe some small test(s) so what I would recommend is to use CFEngine for this purpose. I developed another CFEngine policy that does exactly that task with following in mind:
- all policies have unique names and they are located in multiple source directories somewhere on the hub but outside masterfiles or secondary repository
- in tag named subdirectories (i.e. “tag1”, “tag2”, <IP1>, etc.) inside secondary repository, hard links will be created to policies in source directories
- separation of processing code and data is recommended - into policy file (i.e. “policy1.cf”) and JSON or YAML data file named like policy file, (i.e. “policy1.json”)
- in tag named subdirectories (i.e. “tag1”, “tag2”, <IP1>, etc.) hard links will be created to data files found in source directories too
- if any file (data or policy) found in source directories is prefixed with tag name (i.e. “tag1_policy1.json”) that file will be hard linked in that subdirectory - which enables existence of tag specific files (i.e. Ubuntu vim packages are different from RedHat so I can have “ubuntu_vim_install.json” and “redhat_vim_install.json” data files and one “vim_install.cf” policy file)
- hard links inside subdirectories lose prefix - they are already located in tag named subdirectory (i.e. ubuntu_vim_install.json links to vim_install.json)
- in each subdirectory there will be validation timestamp file created, that indicates changes on files
- all files and links that do not belong in subdirectory must be removed
This diagram shows how the file sources are transformed when copied to
the destination.
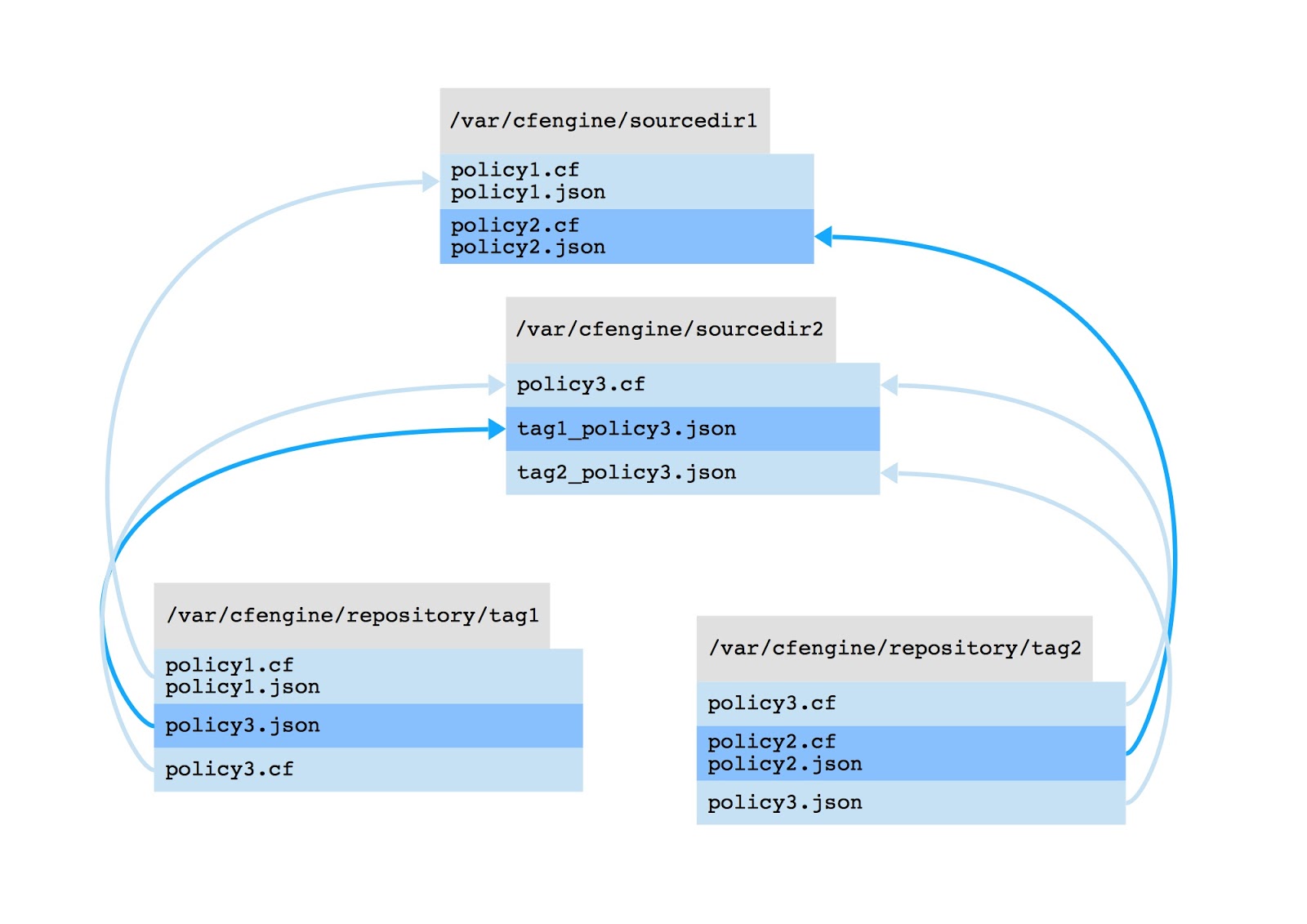 Just to emphasize: “policy3.cf” is used (link created inside
directories) both with computing nodes tagged with “tag1” and “tag2” but
they use different data files (prefixed with tag name in subsubdirectory
named “sourcedir2”).
Just to emphasize: “policy3.cf” is used (link created inside
directories) both with computing nodes tagged with “tag1” and “tag2” but
they use different data files (prefixed with tag name in subsubdirectory
named “sourcedir2”).
Demo
Here are some screenshots from my “lab”. I produced them from multiple
computing nodes: CFE hub (jb02-centos7), docker container (jbcontainer2)
on the hub host and another VM (jb01-centos6). On the hub, my repository
directories “/var/cfengine/repository/cfengine” looks like this:
 There are 4 IP tags “172.16.98.(130|135|149|214)” and 4 “named” tags
“jbcontainer(1|2|3-1|3-2)” - resulting in 8 sub directories. Inside
policies source directory it looks like this (example of
“/var/cfengine/repository/policies/database” directory):
There are 4 IP tags “172.16.98.(130|135|149|214)” and 4 “named” tags
“jbcontainer(1|2|3-1|3-2)” - resulting in 8 sub directories. Inside
policies source directory it looks like this (example of
“/var/cfengine/repository/policies/database” directory):
 Linked policy or data files are in blue and there are some tag specific
data files for IP named tags (JSON files prefixed with IP). Inside
some tags subdirectories, it looks like following:
Linked policy or data files are in blue and there are some tag specific
data files for IP named tags (JSON files prefixed with IP). Inside
some tags subdirectories, it looks like following:
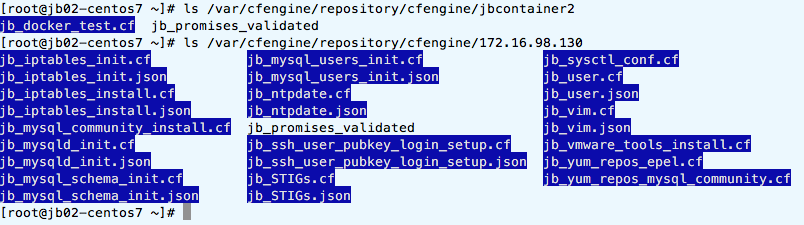 Linked files are in blue and there is validation file named
“jb_promises_validated”. In one of docker container, directory
“/var/cfengine/inputs/services/autorun” contains:
Linked files are in blue and there is validation file named
“jb_promises_validated”. In one of docker container, directory
“/var/cfengine/inputs/services/autorun” contains:
 In
another VM computing node, the same directory contains:
In
another VM computing node, the same directory contains:
 As
it can be seen validation file named “jb_promises_validated” is
suffixed with tag name, for the case when policy files get acquired from
multiple sub directories (tags) on the hub. I have tested this concept
so far with CentOS, Ubuntu, pfSense/FreeBSD and inside Docker
containers. Source code of those policies can be found on my GitHub
here,
here
and
here
and detailed explanation how it works on my blog
here
and
here.
As
it can be seen validation file named “jb_promises_validated” is
suffixed with tag name, for the case when policy files get acquired from
multiple sub directories (tags) on the hub. I have tested this concept
so far with CentOS, Ubuntu, pfSense/FreeBSD and inside Docker
containers. Source code of those policies can be found on my GitHub
here,
here
and
here
and detailed explanation how it works on my blog
here
and
here.
Conclusion
This model enables relatively simple and “clean” deployment of policy files on CFEngine clients. Notably it follows conventions from CFEngine Masterfiles Policy Framework, implying minimal modification to default policy. With separation of policy code and data, it starts resembling Design Center. Further improvements in field of hub policy repository organization and maintenance are possible for sure, which I leave to users. I think that this concept takes us to step closer to simplified “droplets” idea - policy files that can be dropped to hub directory and deployed on clients.


